搜索
关闭


有趣涨知识,深度学习模型的部署
发布时间:2023-06-30
有趣又涨知识,深度学习模型的部署让我们浅浅分享一下吧!在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型从研究阶段转移到实际应用阶段,需要将训练好的模型让其在特定环境中运行。例如,将其部署到移动设备、Web服务器和一些嵌入式设备中,以便能在隔离的条件下也能实时响应提供优质的服务。但是,深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow,由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装,相比于软件部署,模型部署会面临更多的难题,需要对模型进行量化,压缩等优化模型的运行效率。幸运的是,经过工业界和学术界数年的探索,模型部署有了一条流行的流水线,本文对模型的部署以及一些主要的方案作介绍。

1.深度模型的部署通常涉及以下几个步骤:
1)选择合适的框架和平台:选择适合您的需求的框架和平台是非常重要的,因为不同的框架和平台支持不同的模型类型和部署方式。目前比较流行的框架包括 TensorFlow、PyTorch、Keras、Caffe2 等。
2)模型训练和优化:在部署模型之前,需要通过数据训练模型并进行优化。通常,深度学习模型需要在大量数据上进行训练,以获得最佳的预测结果。
3)选择部署方式:选择合适的部署方式也非常重要,因为不同的应用场景需要不同的部署方式。常见的部署方式包括本地部署、云端部署和边缘部署。
4)模型转换和编译:将训练好的模型转换为可以部署的格式,通常包括将模型转换为 TensorFlow Lite、ONNX、TensorRT 或其他格式,并编译为适合部署设备的二进制文件。但当前最好方法是转换为ONNX标准模型,将模型转换成标准的ONNX模型通过Java 或C++加载,实现推理预测,因为ONNX标准已经有非常成熟的可以在各种环境运行的Runtime库。
5)部署和测试:将转换和编译后的模型部署到目标设备上,并进行测试以确保模型的预测结果符合预期。在部署过程中还需要考虑一些性能问题,例如模型大小、速度和精度等。
以上流程较为简单,但是涉及的知识比较广泛。在实际应用中,为了保证模型的精度,我们训练好的模型通常不简单,而实际应用场景往往需要模型速度与精度能达到一个较好的平衡。因此这就需要在算法(剪枝,压缩等)与底层(手写加速算作)去优化模型。在目前也有一些常用的开源加速推理框架,下面给大家介绍一些, 本文推荐3种主要的部署方案,如ONNX、TensorRT和OpenVINO下面将分别做介绍。
2.ONNX
ONNX(Open Neural Network Exchange)是一个开源的深度学习模型交换框架,它可以将不同框架训练的深度学习模型转换为一种通用的中间格式,使得这些模型可以在不同的平台和设备上进行部署和运行。ONNX 是由微软和 Facebook 于2017年推出,已经成为表示深度学习模型的实际标准支持多种深度学习框架,包括 TensorFlow、PyTorch、Keras、Caffe2 等。
ONNX可以提供以下优势:
1)跨框架部署:ONNX 可以将不同框架训练的深度学习模型转换为一种通用的中间格式,使得这些模型可以在不同的平台和设备上进行部署和运行,避免了由于框架不同而导致的兼容性问题。
2)优化和加速:ONNX 可以对转换后的模型进行优化和加速,包括剪枝、量化和混合精度等技术,以提高模型的性能和效率。
3)便于扩展:ONNX 是一个开源的框架,可以方便地扩展和定制,以满足不同应用场景的需求。
4)与云端部署集成:ONNX 可以与云端部署平台(如 Azure、AWS、Google Cloud 等)集成,以便于在云端进行模型训练和部署。
应用场景:
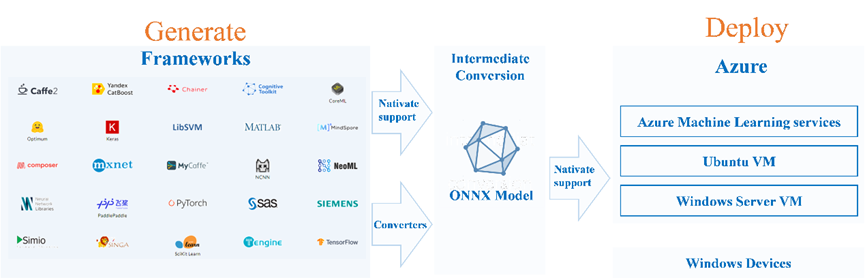
图1 ONNX 模型部署应用场景
上图主要来自ONNX官网与自动驾驶之心博主的思路整理, ONNX文件不仅存储了神经网络模型的权重,还存储了模型的结构信息、网络中各层的输入输出等一些信息。目前,ONNX主要关注在模型预测方面(inferring),将转换后的ONNX模型,转换成我们需要使用不同框架部署的类型,可以很容易的部署在兼容ONNX的运行环境中,为了帮助快速理解与使用在此使用了博主自动驾驶之心的详细描述。更多详细信息参见ONNX的官方网站。
3.TensorRT
TensorRT(TensorFlow Runtime)是 NVIDIA 公司推出的一个高效的深度学习推理引擎,可以加速深度学习模型的推理过程。TensorRT 可以将深度学习模型优化为高效的计算图形,包括网络剪枝、层合并、精度缩减和内存优化等技术,从而在 NVIDIA GPU 上实现高速、低延迟的推理性能。
TensorRT 有以下几个优势:
1)高效加速:TensorRT 可以对深度学习模型进行优化,从而在 NVIDIA GPU 上实现高速、低延迟的推理性能。与 CPU 相比,GPU 可以提供更快的计算速度和更高的并行度,从而在处理大规模深度学习模型时可以提供更好的性能。
2)低延迟:TensorRT 可以将深度学习模型优化为高效的计算图形,从而减少推理时的计算延迟,提高响应速度和实时性能。
3)灵活性:TensorRT 支持多种深度学习框架,包括 TensorFlow、PyTorch、Caffe 和 ONNX 等,可以满足不同应用场景的需求。
4)易于部署:TensorRT 可以轻松部署到 NVIDIA Jetson、NVIDIA DGX 等设备上,提供简单易用的 API 和工具链,以便于快速部署和运行深度学习模型。
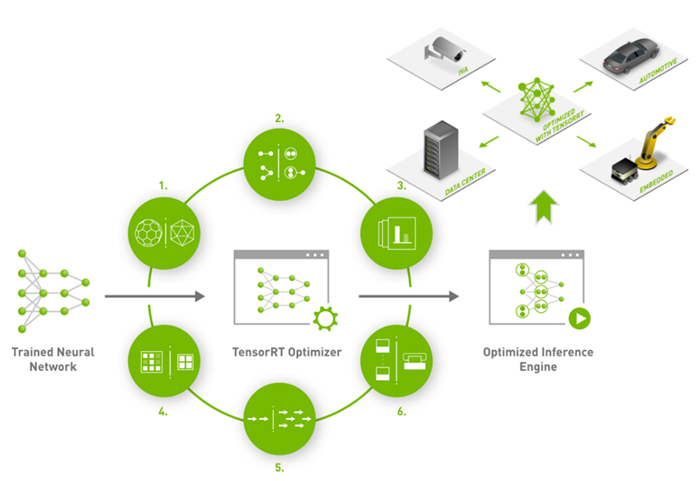
图2 TensorRT 模型优化简图
上图来源TensorRT官网,里面列出了TensorRT使用的一些技术实现过程,可以看出模型量化、动态内存优化、层的融合等技术均已经在TensorRT中集成了,这能够极大提高模型推理速度。总体看TensorRT将训练好的模型经过优化技术转化为了能够在特定平台(GPU)上以高性能运行的代码,生成最终图中呈现的Inference Engine,而后去完成一些实际应用中的任务推理,该部分引用了的一些自动驾驶之心详细描述。
此外,TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地从框架(例如 Caffe 2、Chainer、Microsoft Cognitive Toolkit、MxNet 和 PyTorch)中将 ONNX 模型导入到 TensorRT。请单击此处,详细了解 TensorRT 中的 ONNX 支持。
4. OpenVINO
OpenVINO(Open Visual Inference and Neural network Optimization)是 Intel 公司推出的一个深度学习推理引擎,可以加速深度学习模型的推理过程。OpenVINO 可以将深度学习模型优化为高效的计算图形,包括网络剪枝、量化和混合精度等技术,从而在 Intel CPU、GPU、VPU 和 FPGA 上实现高速、低延迟的推理性能。
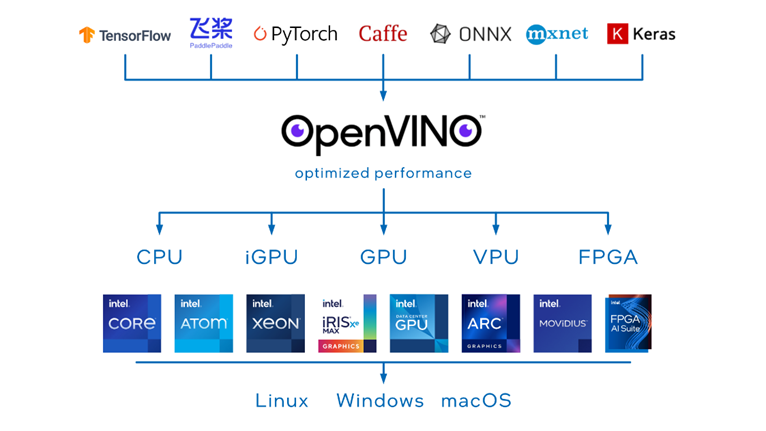
图3 OpenVINO 可支持平台概览
4.1 OpenVINO 的工作流程
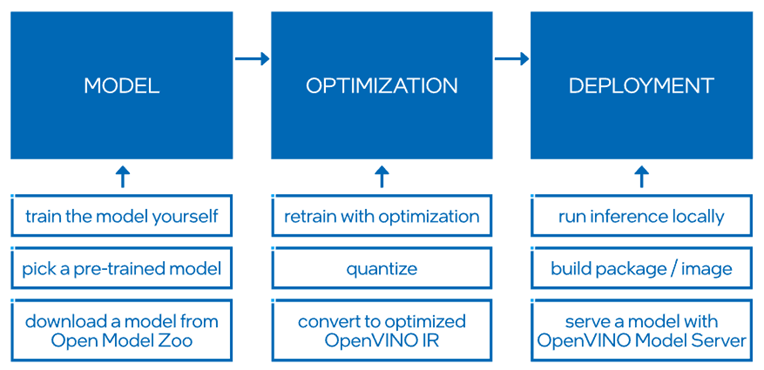
图4 OpenVINO 工作流程
OpenVINO Runtime 使用积极的图形融合、内存重用、负载平衡和跨 CPU、GPU、VPU 等的推理并行性自动优化深度学习管道。您可以将额外的预处理和后处理操作集成并卸载到加速器,以减少端到端延迟并提高吞吐量。
4.2高效模型量化和压缩
通过 OpenVINO 的训练后优化工具和神经网络压缩框架中提供的量化和其他最先进的压缩技术,进一步提高模型的速度。这些技术还可以减少您的模型大小和内存要求,使其能够部署在资源受限的边缘硬件上。
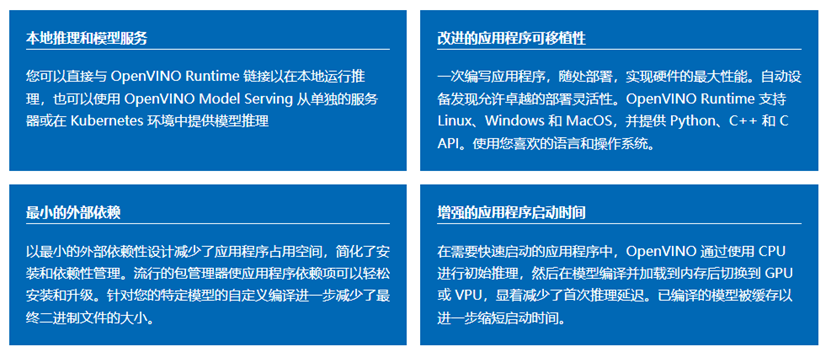
图 5高效模型量化和压缩优势
OpenVINO在模型部署前,首先会对模型进行优化,模型优化器会对模型的拓扑结构进行优化,去掉不需要的层,对相同的运算进行融合、合并以加快运算效率,减少内存拷贝;FP16、INT8量化也可以在保证精度损失很小的前提下减小模型体积,提高模型的性能在部署方面,OpenVIVO的开发也是相对比较简单的,提供了C、C++和python3种语言编程接口,为了帮助快速理解与使用在此使用了博主自动驾驶之心的详细描述。
图6 C、C++和python3种语言编程接口
4.3使用方法
在继续之前,请确保您已安装 OpenVINO Runtime并设置环境变量(<INSTALL_DIR>/setupvars.sh针对 Linux 或setupvars.batWindows 运行,否则,OpenVINO_DIR变量将无法正确配置以传递find_package调用)。
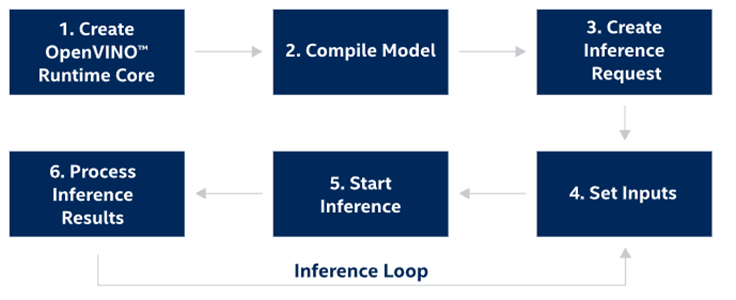
图 7 OpenVINO 使用步骤
5. 本文中提及的网摘内容链接部分见下
【1】ONNX官网:https://onnx.ai
【2】TensorRT:https://developer.nvidia.com/zh-cn/tensorrt
【3】OpenVINO:https://docs.openvino.ai/2023.0/home.html
【4】自动驾驶之心博主:https://www.zhihu.com/question/549284314/answer/2841403684
 loading......
loading......